可变腿长、能下楼、走沙坑,数研院具身四足机器人控制取得突破
近日,上海数字大脑研究院(简称 “数研院”)成功用强化深度学习方法,将 Transformer 大模型应用于四足机器人跨地形、跨具身运动控制,让不同具身的四足机器人成功在多种真实复杂地形上 “化险为夷”,如履平地,为自由、自主的运动控制奠定基础。相关成果以两篇论文的形式发表在国际机器人顶级会议 ICRA 2023 上。(文末附文章链接)
四足机器人运动控制的发展现状
足式机器人常见的有双足机器人和四足机器人,相比其他类型的机器人(例如轮式,履带式),它们有着更好的灵活性和通过性,可以通过更多复杂地形。因此足式机器人的运动控制一直是机器人领域研究热点之一,在代替人类巡逻,搜救,故障检测,服务,侦查等现实场景中有着较为广泛的应用场景。
足式机器人的运动控制大体上可以分为两类方法。一类是基于传统的控制方法,例如轨迹优化(trajectory optimization)和模型预测控制(model predictive control)。这类方法往往要求算法设计者有着充分的特定领域知识,如控制机器人的运动学方程、地面的形状、摩擦系数等。然而,这在复杂地形中往往是难以实现的。相比之下,另一类深度强化学习方法则更能出色完成通过复杂地形的任务。在模拟器中直接训练一个神经网络,再将其迁移到真实世界中,这种策略称为 “模拟到真实的迁移(sim-to-real transfer)”。深度强化学习可以在很大程度上减少对特定领域知识的依赖,且训练出的策略往往表现出更强的鲁棒性,因此被认为是足式机器人运动控制的一种具有前景的方法。
传统深度学习模型的容量有限,难以支持机器人在更复杂的地形环境中的控制,目前为止,大部分强化学习算法都只针对一个固定的机器人具身(embodiment)进行训练。强化学习训练完成的控制器只能应用于一个机器人,一旦机器人的硬件特性发生改变,其控制器往往需要从头开始训练。近年来,一些基于强化学习方法尝试为不同具身(例如不同形状)的机器人设计通用控制器,例如使用模块化网络架构、基于机器人条件的策略、基于图神经网络的方法。但部分方法目前仅在仿真环境中进行验证,未在真实机器人上验证可行。由于机器人形态与控制方法之间复杂的关系,设计一个跨具身的机器人控制器目前还是一个有挑战性的问题。
以 Transformer 序列模型为基础的控制框架 TERT 和 EAT
相比传统深度学习模型,Transformer 序列模型有着更大的模型容量以及更强的泛化性,在自然语言处理和计算机视觉等领域的复杂多任务上取得了不错的成绩。因此,我们探究将 Transformer 模型应用于足式机器人控制的可能性,并提出了针对跨地形四足机器人运动控制框架 Terrain Transformer(TERT)和跨具身的四足机器人运动控制框架 Embodiment-aware Transformer(EAT)。
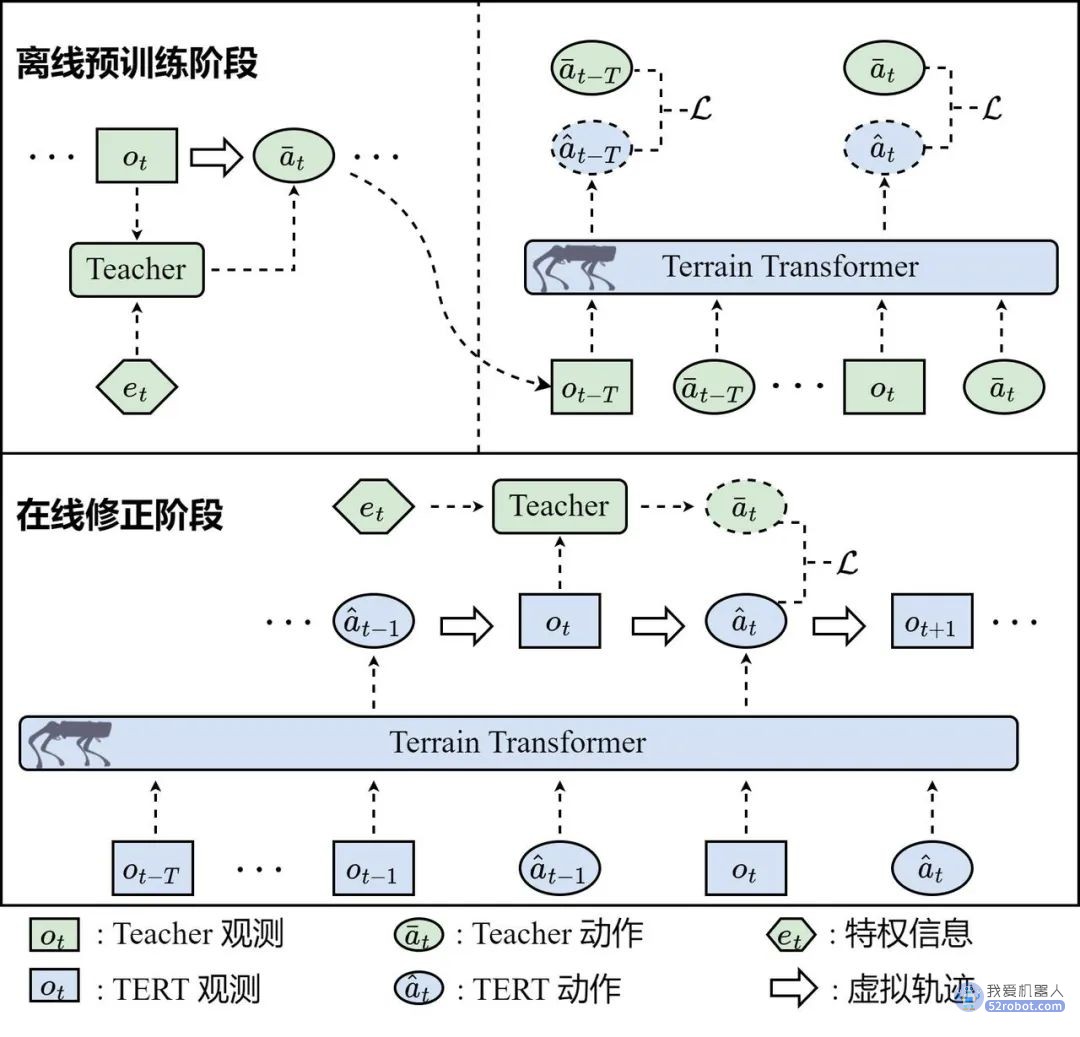
图一:Terrain Transformer 训练框架
如图一所示,TERT 训练框架包括离线预训练和在线修正两个阶段。首先在离线预训练阶段,我们借鉴广泛应用于机器人控制的特权学习(privileged learning)方法,在模拟器提供特权信息(如地形信息,物理参数)的情况下使用强化学习算法训练一个教师策略(Teacher Policy),以最大化设定的奖励函数。教师策略可以在模拟器中取得近似最优的成绩,但却无法在真实世界直接应用。之后,我们使用教师策略和模拟器交互搜集数据,并训练 Transformer 根据过往历史 T 步的观测、动作序列预测教师动作。
通过离线预训练阶段得到的 Transformer 模型虽然可以在教师策略搜集得到的数据集上达到较小的损失函数,但在测试时却并不能达到满意的效果。这是因为在测试时 Transformer 输入中的动作序列并不是来自教师策略,而是来自本身 Transformer 之前的输出动作,动作序列的不同会间接导致输入的观测序列的不同,从而进一步影响算法的性能。为了解决这种由输入分布不同所带来的性能影响,我们提出在离线预训练阶段后加入一个在线修正阶段。具体地说,在线修正阶段(图一下方),使用 Transformer 输出的动作和模拟环境交互,同时使用教师策略给出目标动作,之后再训练 Transformer 根据自己经历过的观测、动作序列作为输入预测教师的动作。

具有可变前后腿长度以及躯干长度的四足机器人
而对于跨具身的四足机器人控制,数研院引入向量 e 表示机器人具身,e 包括机器人前小腿长度、后小腿长度与躯干长度等。EAT 通过在模拟器中训练 M 个不同具身的机器人控制策略,并使用这 M 个策略分别搜集对应具身下的专家数据。为了使得 Transformer 模型能完成多种具身的泛化,每条轨迹还会包括搜集数据的机器人具身向量 e。之后,EAT 在混合专家数据集上训练 Transformer,通过历史观测、动作以及具身向量 e 预测下一个专家动作。
四足机器人真机实景实验
数研院首先在宇树的 A1 四足机器人上对比了 TERT 与其他方法在不同地形上的控制效果,TERT 可以成功通过九种复杂的地形。相比之下,使用传统强化学习方法控制的机器人可以在简单地形,比如上下坡上正常行走,但却无法通过较难的地形,比如沙坑,下楼梯。

数研院方法 TERT(上坡)

传统强化学习方法(上坡)

数研院方法 TERT(沙坑)

传统强化学习方法(沙坑)

数研院方法 TERT(下楼梯)

传统强化学习方法(下楼梯)

数研院 TERT 在九种地形上的表现
之后,在可变具身的 Mini Cheetah 机器人上验证了 EAT 模型和其他方法。EAT 模型可以在前后腿一样长、前腿比后腿短、前腿比后腿长三种具身类型上完成较好的泛化。

具身 1:前后小腿一样长

具身 2:前小腿比后小腿短

具身 3:前小腿比后小腿长
使用 EAT 模型的另一个优越之处在于机器人可以根据所处环境的不同变化自身的身体,达到一种类似进化(evolution)的方式。例如,当机器狗发现正常具身难以下楼梯时,可以选择更长的躯干、更长的前腿和更短的后腿,最终得以通过楼梯。

未来,数研院将探索把视觉信息引入 Transformer 模型的控制中,进一步实现决策大模型在更复杂多样的环境上的鲁棒控制。
两篇中稿 ICRA 2023 的论文链接如下,感兴趣的小伙伴可以进一步了解:
1.Sim-to-Real Transfer for Quadrupedal Locomotion via Terrain Transformer:https://arxiv.org/abs/2212.07740
2.Multi-embodiment Legged Robot Control as a Sequence Modeling Problem:http://arxiv.org/abs/2212.09078
声明:本站所有文章资源内容,如无特殊说明或标注,均为采集网络资源。如若本站内容侵犯了原著者的合法权益,可联系本站删除。





















