大模型时代下的机器人应用:我们离具身智能还有多远?
在大模型以其超前的文本输出、逻辑推理能力出现在人们面前时,“具身智能”这一概念又一次把通用人工智能的可能性推到了人们面前。一种以定位感知模块为输入,以大模型为“大脑”进行逻辑推理和规划,以传统控制模块为“小脑”执行大模型的决策的机器人算法框架使得可以执行长序列复杂任务的机器人几乎成为了现实。

图源:Bing AI
当然,这一美好想法并没有那么容易实现,而横亘在理想和现实之间的主要问题之一,就是当前机器人领域芯片算力严重不足,难以满足日益增长的机器人应用的算力需求,导致机器人操作的硬实时性很难被满足。
我从 2018 年开始进入机器人这个领域,希望在这篇文章里提出一个目前还尚未被大量关注到的思路:一个合适的模版可以为多个机器人领域的算法和应用提供硬件定制化的基础,甚至能加速芯片自动生成这一计算机体系结构所有难题中的明珠问题的解决。
传统的机器人算法框架通常包括了感知、定位、规划、控制等几个模块。当前除了感知模块被深度学习网络算法统治之外,其余的几个模块在不同场景下的机器人应用中变化还是较大的。
根据传感器数量、种类、机器人的应用模式的变化,定位、规划和控制模块的算法变化也较大。以定位算法为例,可以使用的传感器包括单目相机、双目相机、激光雷达、GPS、IMU 等等。快速变化的算法框架和形式也使得为机器人算法定制芯片变得困难。为某一个算法设计的硬件有时难以运行其余算法,极大地减少了硬件平台的移植性,增加了成本。
01
因子图:优化类算法的理想硬件加速模版
以定位算法为例,常见的算法框架通常可以被分为前后端两个部分,前端通常被用于提取特征点,计算描述子,寻找对应关系并将特征信息传递给后端。后端通常负责根据前端的特征信息对机器人位姿进行优化。前端特征提取利用传统的 SIMD 硬件可以得到充分的加速,而后端的优化算法则因为其不规则的运算更难被加速。
如此一来,后端的优化算法会成为整个定位模块的瓶颈。我们发现,不仅是在定位算法中,在路径规划、控制等多个算法中,都存在类似的问题。
优化算法,以牛顿高斯消元法为例,在传统的加速器设计中一直是难以解决的一环。这一问题难以被加速主要原因在于两点:
首先,优化过程中涉及到大量的矩阵乘法、矩阵分解等矩阵操作。这些矩阵的规模较大,通常维度可以达到几百行、几百列,而且除了矩阵乘之外,其余操作很难并行化。如此大规模的不规则矩阵运算,除了堆积算力规模之外,并无其他更好的加速方法。
另外,尽管优化过程中的矩阵并不稠密,常常只有百分之十以下的元素为非零元素,但这些矩阵的稀疏性并不规则,难以被利用。
我们提出使用因子图为中间模版来对机器人应用中的优化算法[1][2]进行加速。因子图是一种描述变量关系的二分图,可以被应用于优化问题的描述中。因子图中有两种不同的节点——变量节点和因子节点。变量节点即一系列需要优化的变量,而因子节点即为变量节点之间的连接和约束。在图 1 中,我们展示了一个因子图与定位算法优化后端的关系。
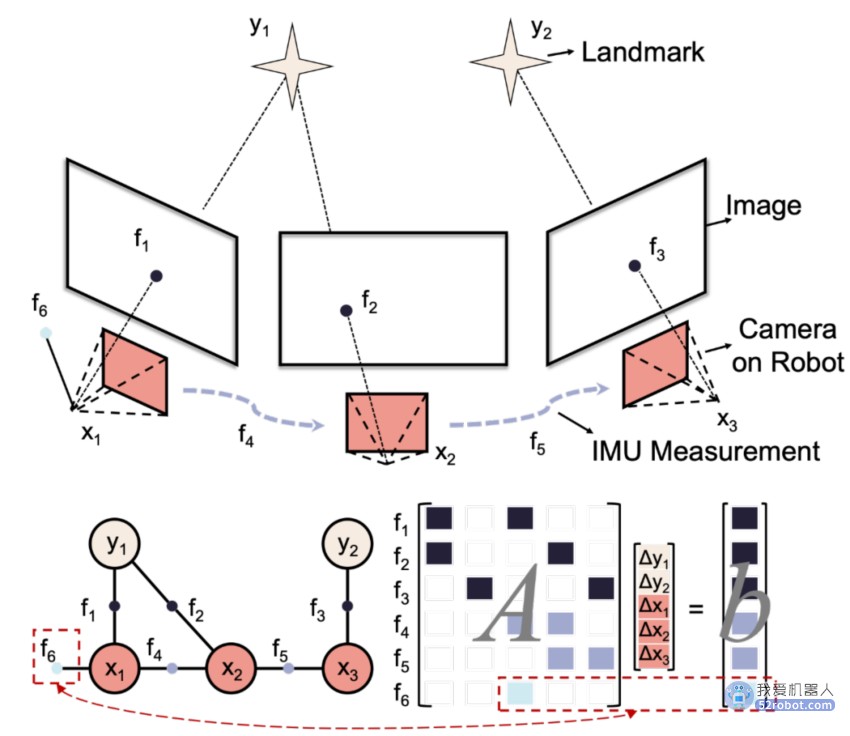
图 1 定位算法因子图示例
以高斯牛顿解法为例,后端优化往往将整个过程转换为解非线性方程组 Ax=b,将 x 解出后带回到 x 的初始值中并判断收敛条件是否满足。我们发现,求解 Ax=b 的过程则与因子图可以直接联系起来。具体来说,因子图的每一个节点,无论是因子节点或变量节点,都对应着矩阵 A 与向量 b 的某些位置。
在图 1 这一例子中,变量节点 x1 到 x3 表示了机器人在三个时间节点的位姿,y1 和 y2 表示两个物理世界中的标志,而 f1 到 f5 分别表示了不同传感器中采集的数据。f1-f3 位相机观测因子,f4、f5 位 IMU 观测节点,f6 表示前序位姿。所有节点构成了图 1 左下方的因子图,同时也构成了矩阵 A 与向量 b 的结构,他们二者之间的关系如图 1 中箭头所示。
如前文所述,在绝大多数机器人应用中,矩阵 A 的规模较大而稀疏度较高。直接求解 A 会带来极高的延时与功耗负担,而希望利用到矩阵的稀疏性时,其稀疏度又不够结构化。绝大多数加速求解稀疏矩阵的方法也并不能带来很好的加速比,导致在定位、规划、控制等多个模块中,优化算法都成为了加速算法性能的阻碍。
利用因子图可以很好地解决这一问题。因为因子图的结构对应了稀疏矩阵中稠密的非零元素,依据因子图展示的变量顺序,完全可以将大的稀疏矩阵求解转换成多个小的稠密矩阵求解。这么做第一可以减少硬件资源的消耗,不需要构建大规模的矩阵操作单元,第二则可以提升硬件资源的利用率。图 2 就展示了一个对图 1 中所建立的因子图的一个变量先进行局部消元的例子。
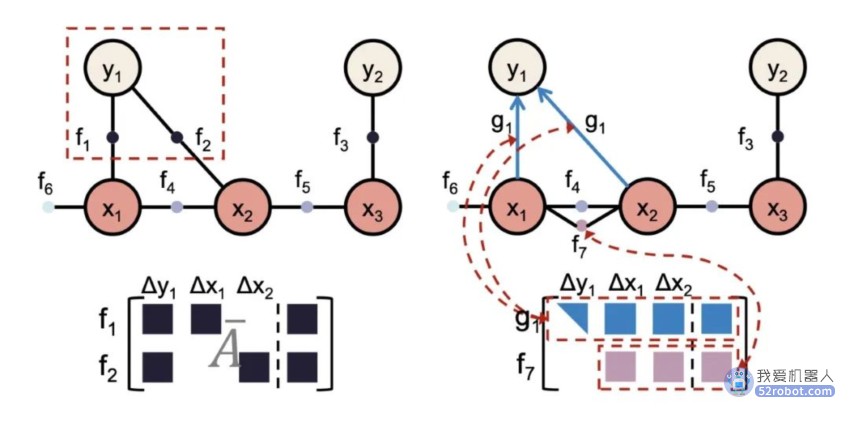
图 2 逐步对因子图中涉及到的变量进行消元
在这个例子中,由于原始矩阵维度过大且稀疏度较高,无论使用 CPU 或是 GPU 对其计算都难以达到实时性需求。而使用因子图对其进行维度降低后,配合专用的矩阵加速单元,我们实现了对常见的桌面 Intel i7 处理器 9.3 倍的加速比,节约了超过 50 倍的能耗。对于常见的嵌入式 ARM 处理器,实现了 47.6 倍的加速比,节约了 16.8 倍的能耗。以因子图为加速模版的定位算法加速器,可以实现接近 100fps 的定位算法运行速度,达到了机器人应用中的实时性需求。
基于这一思想,我们又为规划算法设计了一套以因子图为模版的硬件加速单元。我们在设计中进一步发现,在确定了完整的因子图后,从哪个因子开始消元会带来硬件资源的极大不同。
以图 1 和图 2 为例,对于完整的因子图,我们选择图 2 从左上角的 y1 节点开始消元。其实从右边的 y2 节点,或中间的 x2 节点,都可以完成对因子图的消元并求解出对应的变量节点。从不同的因子节点开始求解,将会带来完全不同的矩阵运算维度、计算速度和硬件资源消耗。
直接估计每一种消元顺序的消耗是很难的,因为如果有 N 个节点的话,会有 N 的阶乘种消元顺序,对每一种顺序进行硬件资源的分析是极难的。我们创造性地提出使用软件的方法来估计硬件资源的消耗,从而快速评估不同的消元顺序对硬件资源的使用。我们使用了三种软件上的指标,分别是消元过程中的最大矩阵维度、平均矩阵维度和平均矩阵密度。这三种软件上的指标分别对应了所需最大硬件资源、平均加速比和硬件利用率。对于特定的规划算法,我们还专门提出了一种领域专用的双向消元方法。利用特定的双向消元方法,相比于随机选取消元起点,还可以继续提升超过两倍的性能。
02
机器人应用硬件设计的自动化
当使用了因子图作为硬件设计模版之后,我们可以大幅提高机器人领域多种算法的运算性能,包括定位、路径规划、控制等算法。然而,即便是对因子图和硬件设计最熟悉的研究人员,也需要长达数月对单一算法的专用加速器进行设计,而机器人领域存在着难以计数的不同种类算法。如果使用常见的 High Level Synthesis(HLS,高层次综合)对硬件进行自动生成,则会因为缺乏定制化的能力而导致无法利用特殊的数据流[3],难以实现性能的大幅提升。
当以因子图为模版对机器人的多个算法进行加速之后,我们意识到,因子图可以作为一个非常通用的模版,方便我们对机器人领域的硬件自动设计进行突破。直接将软件映射到硬件电路的难度很高,而因子图给我们提供了一个非常好的中间介质,我们可以分两步进行硬件的自动化设计:首先将机器人算法映射到中间介质上,再将中间介质映射到硬件电路中去。

图 3 使用因子图作为中间变量的硬件设计自动化
整体工作流程如图 3 所示,我们针对机器人应用,提供了一个完整的优化算法的自动设计框架,使用者只需要依据我们的软件框架对其所需要的软件算法进行定义,编译框架会将用户的算法自动映射到因子图的结构上去。同时,依托因子图的结构,编译框架会进一步生成基础的矩阵操作的指令。根据这些指令和其数据流,会依赖一些矩阵运算的模版电路,自动生成整体的机器人专用架构,实现硬件生成的自动化。
我们的工作整体上实现了三个大的贡献。首先,提出了一个新的位姿表示,可以被应用于多种机器人领域的应用。通用的位姿表示可以方便不同的机器人应用使用同样的中间媒介(因子图)。其次,我们提出了一套完整的编译框架,对于开发者极其友好。开发者只需以构建因子图的形式进行编程,而无需关心背后的位姿表示、数学推导等等过程。最后,我们提出了端到端的硬件生成方式,对比传统的 HLS 硬件生成方式,大幅提高了硬件对于机器人算法独特的数据通路的应用,实现性能提升。
03
机器人应用的未来:硬件赋能具身智能
机器人领域的算法和应用的变化是日新月异的,传统的机器人 OODA 决策环在大模型涌现之后,出现了很多新的变化,大模型取代传统的决策和规划算法之后为机器人产业带来了大量的新的机会。因为大模型涌现的决策和任务分解能力,机器人可以开始执行长序列的复杂任务,实现真正的智能化。
尽管这种愿景非常美好,但现实与愿景之间仍存在着很大的鸿沟。一个最重要的问题就是当引入大模型进行决策之后,机器人控制的实时性问题。机器人的控制算法通常需要的频率高达几百赫兹,而以现有的运算能力进行大模型推理则远难达到这一频率。这也就导致了机器人控制难以实现实时性,还远没有达到可以投入实际使用的地步。
我们希望能通过硬件与系统上的创新来解决这一问题。系统层面,希望提出大小模型分层的机器人算法架构。在任务理解及分解时,使用较大的模型但以较低的频率参与工作,对机器人进行较长期的任务规划。在执行任务时,使用小规模的模型,保证分解任务正确执行的同时提高实时性。采用端云分层的执行思路,将小模型放在端侧进行硬件加速。我们认为,系统和硬件的定制化才是真正赋能具身智能的最有力的武器。
04
总结
机器人的智能化一直是这一产业进化的核心目标,我们希望机器人能正确高效地执行更复杂的任务,为人类提供服务。随着算法的不断演进,机器人应用对于算力的需求也日益增加。作为硬件架构的研究者,面对日新月异的机器人应用,这对我们来说既是机遇也是挑战。尤其是在大模型逐渐占领机器人控制领域的今天,如何实现实时性地大模型控制、保证机器人正确高效地执行任务,期待我们和大家一起对这些问题给出自己的回答。
参考文献
[1] Hao, Yuhui, et al. "Factor Graph Accelerator for LiDAR-Inertial Odometry." Proceedings of the 41st IEEE/ACM International Conference on Computer-Aided Design. 2022.
[2] Hao, Yuhui, et al. “BLITZRANK: Factor Graph Accelerator for Motion Planning.” 60th Design Automation Conference (DAC), 2023.
[3] Liu, Weizhuang, et al. "Archytas: A framework for synthesizing and dynamically optimizing accelerators for robotic localization." MICRO-54: 54th Annual IEEE/ACM International Symposium on Microarchitecture. 2021.
声明:本站所有文章资源内容,如无特殊说明或标注,均为采集网络资源。如若本站内容侵犯了原著者的合法权益,可联系本站删除。











是什么?")









