机器人技术:多物体场景下“机器人操作”的算法和系统

机器人对多个对象的操作是一个重要的应用主题,包括仓库自动化、执行清洁的服务副机器人和大规模对象分类。尽管问题的复杂程度可以从几个物体到大的无序堆,但由于机器人和所有物体的高维关节配置空间,物体交互的复杂动力学,以及由杂波引起的模糊和遮挡,自主性仍然是一个重大的技术挑战。本文广泛调查了经典和最先进的多对象操作研究,并按照任务、感知、预测模型和决策算法的维度对它们进行了分类。它还涵盖了在实践中实现健壮的多目标操作系统的持续努力中所面临的新趋势和开放问题。

第一部分:多对象操作任务分类
通常,多对象操作任务在数学上被指定为试图将属于机器人和对象的联合状态空间的状态带入满足特定目标条件的状态。定义机器人的状态空间为xR∈CR, m个对象的状态空间为x1(t)∈C1,…,xm(t)∈Cm,关节的状态空间为笛卡尔积C = CR × C1 ×···×Cm。我们进一步表示工作空间为X,机器人几何结构所占用的体积为R(xR),物体所占用的体积为Oi (xi)。特定操作的目标是达到某个目标子集Cgoal C,同时将状态保持在自由空间Cfree C。不同的操作任务的特征在于它们的动作集、目标条件、可行性条件、观察空间或控制对象的动态模型。过去的文献主要根据目标集Cgoal∈C的差异对任务进行分类,如下所述。
1、Singulation:在杂物堆中的抓取,多个物体可能需要移动才能抓取一个特定的物体。最近的研究倾向于认为当完成最终的抓取时,问题就解决了。
2、Navigation:移动机器人在混乱的环境中行进,到达目标区域,一组可移动的物体挡住它的路径。Navigation被研究为离散搜索问题或推箱子游戏,其中机器人和物体都沿着轴对齐的网格边缘移动。也可以表述为连续运动规划问题,如图1所示。

3、Declutter:给定一个区域Xclear要清除,将一组对象移离目标区域。整理与运筹学和运动规划中的经典问题——拆卸问题密切相关。
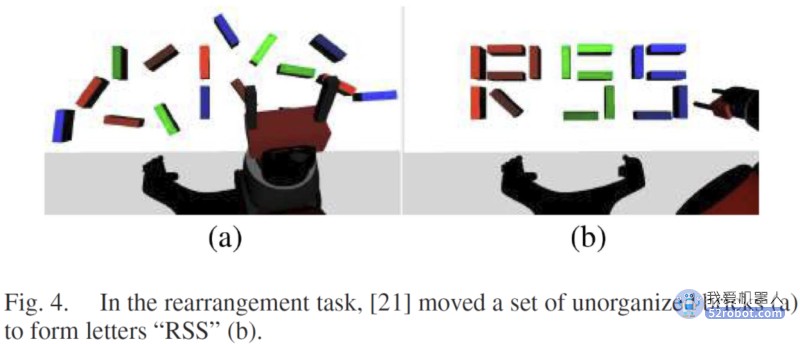
4、 Rearrangement: 将一组对象移动到一组指定的目标位置。Rearrangement任务可以标记为每个对象具有单一指定的目标配置。在这两种情况下,对象的操作顺序和操作路径可以看作是两个子问题,其中操作顺序的决策空间是离散的,操作路径的决策空间是连续的。这种离散-连续分解使得有效的规划算法得以发展。

5、 Packing:与declutter相反,将一组对象移动到目标区域,但该区域内每个对象的目标构型未指定。包装在性质上有两种不同的说法:松散包装和密集包装。在松散包装中,目标区域的体积比待包装对象大得多,因此重点是将对象运输到该区域。因此,之前的工作以任意顺序使用顺序单对象操作,很少依赖于已经打包的项目。在密集包装中,目标区域的体积近似于物体体积之和,因此必须规划物体的配置以提高堆积密度。
6、 Placing:将一个新对象放入目标区域。放置在性质上也有两种不同的说法::松散放置和密集放置。在松散放置中,物体的密度较低,可以通过将其他物体移出目标区域来实现放置。在密集放置中,物体的密度很高,障碍物物体可能会干扰其他物体,因此必须仔细规划物体的运动顺序和轨迹,以提高成功率。放置与包装密切相关,可以通过反复放置新的物体来实现,现有的所有物体包装都是这样做的。
7、Sorting: 一组对象,被划分为类(例如,颜色、身份或类型),应该在几何上进行分离。分类有两种:聚类分类和打包分类。在聚类分类中,目标是最小化类内距离和最大化类间距离,类似于单数的多类扩展。在打包分类中,目标是将同一类的所有对象移动到指定的目标区域,类似于打包的多类版本。

在多对象操作中有一个普遍的共性,即大多数任务可以被建模为包含离散任务的任务和运动规划(TMP)问题,即选择要操作的对象,以及连续运动,即选择目标位置和操作运动。然而,一般模型在计算上不太可能是有效的。相反,特定于任务的算法和启发式因为其速度和解决方案的质量而更受欢迎。在表中可以找到一些用于分类不同任务的角度。
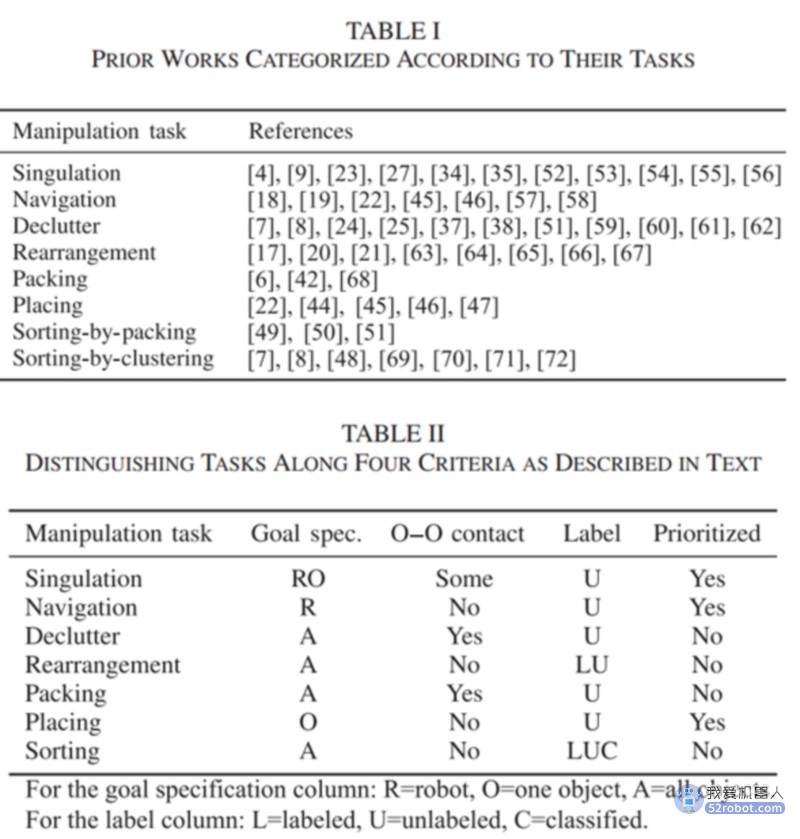
目标确认(机器人/一个物体/所有物体):调偏任务要求机器人对目标物体的把握,而导航任务只指定机器人的目标配置。放置只涉及单个对象。其他任务通常假定指定所有对象的目标配置。
物体-物体接触:有些任务要求机器人同时与多个接触物体进行交互,例如,正在整理或包装的物体堆。一些先前的工作在singulation使用推将多个对象推离目标对象。在没有多个物体接触的情况下,拾取和放置操作本质上是一个几何问题,但除此之外,物体-物体接触的物理预测是一个挑战
对象标记(标记/未标记/分类):导航、整理、标记、打包和放置任务不为单个对象指定目标,使得对象识别不需要完成任务。重排任务可以有标记或未标记的变量。排序任务中的对象可以被标记、未标记或分类,即部分标记,其中一些对象或对象组必须移动到不同的指定区域
优先级(是/否):在许多设置中,机器人可以专注于优先级对象的姿态,而其他对象是辅助的,被视为障碍。例如,导航任务被分为几个阶段,机器人在每个阶段都专注于阻塞道路的物体。优先级可以用来简化算法设计,例如,使用贪婪启发式或通过消除识别和预测辅助对象的需要。然而,即使在这样的任务中,也存在一些具有挑战性的例子,其中机器人必须提前几步推理辅助对象的操作(例如,非单调导航问题)。
第二部分:感知算法
感知——从传感器数据估计对象的状态及其物理属性——在开始操作之前以及在操作期间需要纠正意外事件。由于遮挡,在混乱的场景中,准确的感知尤其困难。此外,在非结构化环境中很难获得物体几何、惯性特性、摩擦特性和相互作用行为的精确模型。因此,多目标操作的感知仍然是一个重大的研究挑战。
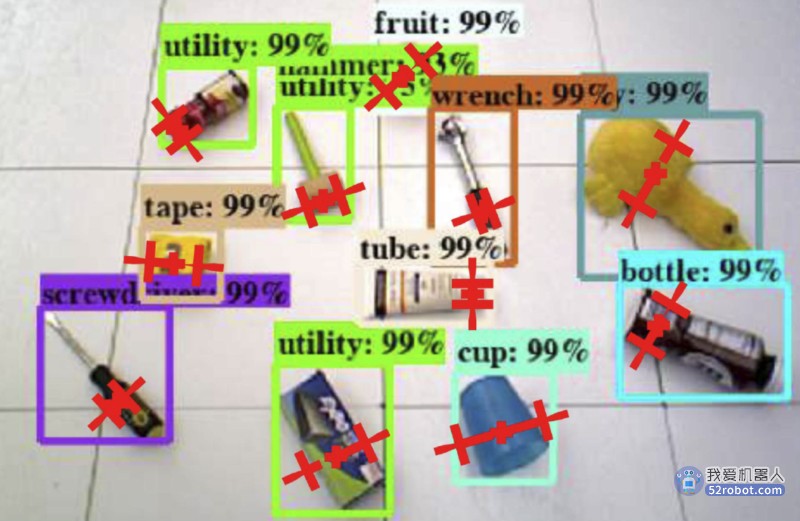
我们注意到,对多目标操作的感知研究比操作规划研究最近获得了更多的关注。该领域的早期工作,如假设已知和/或视觉上不同的孤立物体的无遮挡、自上而下视图。直到最近,研究人员才开始解决遮挡下的感知,并处理不确定性和模糊性。复杂的假设生成算法考虑了传感器数据拟合、稳定性和其他标准,已用于确定可能的假设对象排列。最近,深度学习技术的使用也有了显著的增长,这种技术可以从相机图像中识别物体及其属性。相关工作解决了可提供性检测,这是直接从视觉数据预测可用于操作的动作选择(例如,抓取候选对象)的问题。由于使用了深度学习技术,可以直接从相机图像中预测高质量的行动或政策,这一领域正受到关注。在表III中,我们根据所解决的问题、算法和场景总结了代表性的感知方法。
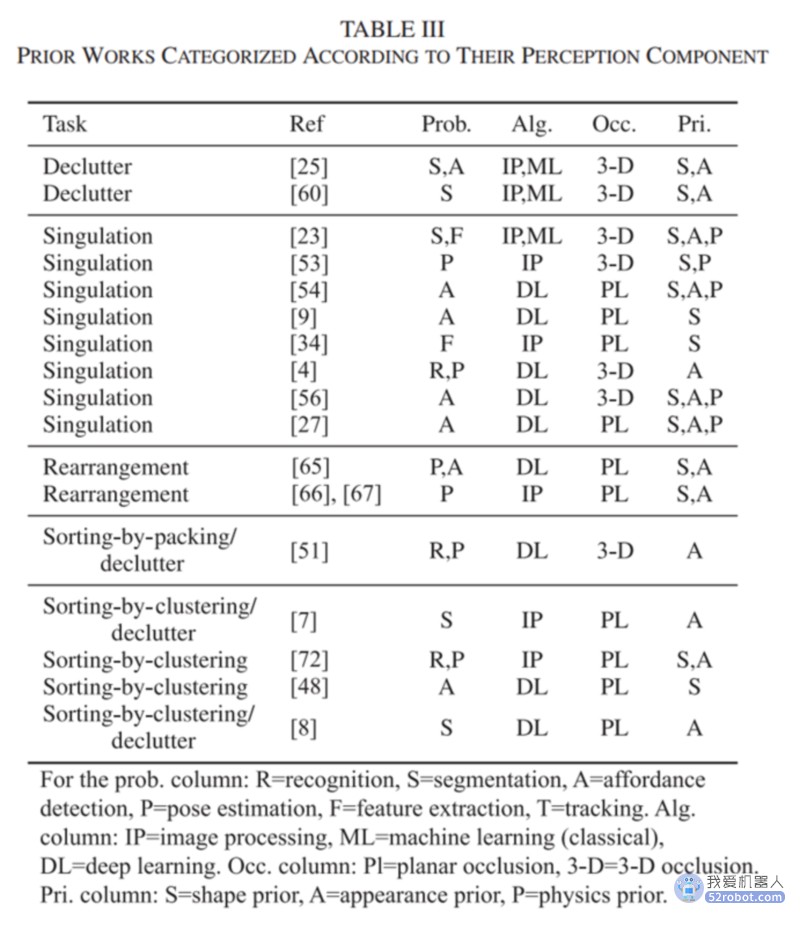
问题(识别/分割/可视性检测/姿态估计/特征提取/跟踪):物体识别的目的是预测图像(如边界框)中物体所在的区域。分割是一种细粒度的识别,其中识别出物体对应的图像像素。姿态估计的目标是为已知物体的参考模型生成2-D/3-D物体姿态,通常还包括物体识别信息。功能域预测以动作选择策略或操作算子的成功率预测的形式提供信息。

特征提取将一个或多个对象的状态总结为一个特征向量,供下游机器学习算法使用。与所有其他在时间离散时间实例中估计对象状态的方法不同,跟踪算法在多帧之间保持对象的姿态。在操纵过程中,它们以实时概率运行。通过使用时间相干性,跟踪可以提高对遮挡和不确定性的鲁棒性。在前深度学习时代,机器学习依赖于人工设计的特征,使用图切和聚类等算法来解决分类和分割问题。相比之下,深度神经网络通过从数据中学习特征来进行端到端工作,其输出可以表示对象位置或可见性。使用卷积金字塔,深度网络可以有效地处理整个图像,这有利于处理多个严重遮挡的物体。

3、遮挡(无/3- d):许多研究在解决桌面问题领域假设从头顶摄像机的角度看物体不重叠。一般的三维遮挡更具挑战性,需要对隐藏物体进行推理。例如,倾斜的摄像机可以看到每个物体至少一个面的大部分。对象搜索任务使用主动感知来定位完全遮挡的目标。
4、先前知识(形状/外观/物理):由于遮挡和部分观察,感知问题通常是不适定的和未确定的,因此使用先前知识来产生更好的估计。形状先验将对象的几何形状限制为具有某些性质,例如,矩形、平面、凸,或者使用场景中的对象来自已知的2-D或3-D模型的知识。外观先验对物体的材料、光照条件或颜色做出假设。物理学将物体的运动方程预先设定为刚性、弹性或塑性变形。使用物理模拟器构建的训练数据也被认为是一种物理先验形式。
总体而言,多目标操作的感知技术正在迅速成熟,但绝大多数实验,包括表III中列出的所有工作,仍然只发生在实验室环境中。实验室设置的结果很可能很好地推广到工业应用中,机器人的环境可以类似地控制,感知算法专门针对所考虑的对象。在自动化仓库,机器人很可能会遇到样本外的物体和不确定的环境条件。未来工作的一个重要方向是研究知觉如何推广到不受控制的实验室环境。
任务依赖的感知系统设计:我们观察到感知算法处理的操作任务分布不平衡,表III中的大部分工作解决了单点任务。这可能是因为抓取发现了很多应用场景,而单点是提高抓取鲁棒性的一种方式。由于在密闭空间内接触物体的密度较大,因此包装和放置任务通常需要在严重遮挡下进行感知,这为未来的感知研究提供了有益的方向。
基于学习的感知的系统集成:最近的趋势表明深度神经网络在感知方面的流行,这与计算机视觉领域的总体趋势一致。在操作方面,深度网络使研究人员能够将学习作为一种更紧密地结合不同系统组件(例如,可提供性、预测和计划)的方式进行研究。
传感器模式:表III中列出的绝大多数感知模型使用视觉和/或深度作为唯一的传感器模式。我们注意到一个例外,其中机器人施加的力被表述为学习预测模型的状态空间的一部分。最近的研究表明,其他模式,如力量和触觉信息,可以补偿视觉和深度,以解决歧义或处理接触丰富的操作问题,但这些方法尚未在多对象操作文献中被利用。
不确定性量化和建模:最后需要注意的是,规划和预测模块通常假设感知是准确的。然而,在现实世界中,感知总是会出错。一个容错的解决方案需要感知和规划模块的协同设计。
第三部分:预测模型
预测模型对于某些决策算法(如模型预测控制)估计操作结果是必不可少的。尽管预测模型在单对象推送设置中获得了一些关注,但多对象操作设置更复杂,因为对象通常通过接触进行交互。这不仅使物理建模更加复杂,而且由于物体间接触模型固有的不确定性,也降低了预测的准确性。
预测粒度是区分以往研究的一个重要特征。对于涉及在平面上拾取和放置动作的任务,先前的研究完全忽略了预测问题,假设每个动作都将按照指定的方式成功完成。更复杂的模型可以预测抓取和放置的稳定性,即高水平动作成功的条件。例如,当决定如何从桩中提取物体或将物体放置在桩上时,机器人必须预测桩的稳定性。另一方面,对于涉及多对象接触的问题,对象行为的低级预测是必要的,例如,推送。在这里,由于接触状态、物体惯性参数和摩擦系数的普遍不确定性,预测可能具有挑战性。
1、 刚体预测模型
运动学/准静态/动态:运动学模型考虑物体上的所有力,只考虑几何约束,如碰撞约束。当机器人可以通过抓取或夹具固定物体,并且物体运动不受接触力的影响时,运动学模型达到高保真度。准静态模型考虑了所有力,但忽略了惯性力和阻尼力,并假设物体总是在外力平衡下运动。当物体移动缓慢,加速度非常小,并迅速衰减为零时,该模型可以做出准确的预测。动力模型考虑所有力,包括惯性力。
基于分析/学习:分析模型来源于经典力学,尽管有些参数可以从数据中预测。基于学习的模型仅从观察(例如,视频或物体特征)来模拟物体的运动。充分理解现象的分析模型可以实现合理的整体保真度,并且不需要昂贵的数据收集和学习步骤。另一方面,当分析方法无法捕捉多个对象之间的微妙相互作用时,学习可以实现更高的保真度。缺点是,由于过度拟合或数据覆盖不足,基于学习的模型的保真度可能会受到影响。
平面/三维:平面模型假设沿重力方向和水平方向的运动/力是可分离的,因此可以忽略沿重力方向的力平衡。三维模型考虑沿所有方向的耦合运动和力。平面模型的使用需要物体之间的关系假设,例如,物体不是在彼此的顶部,物体移动得足够慢,所以它们不会倒塌。基于这些假设,平面模型可以将物体构型空间的维数降低一半[SE(3)→SE(2)],并显著提高效率。
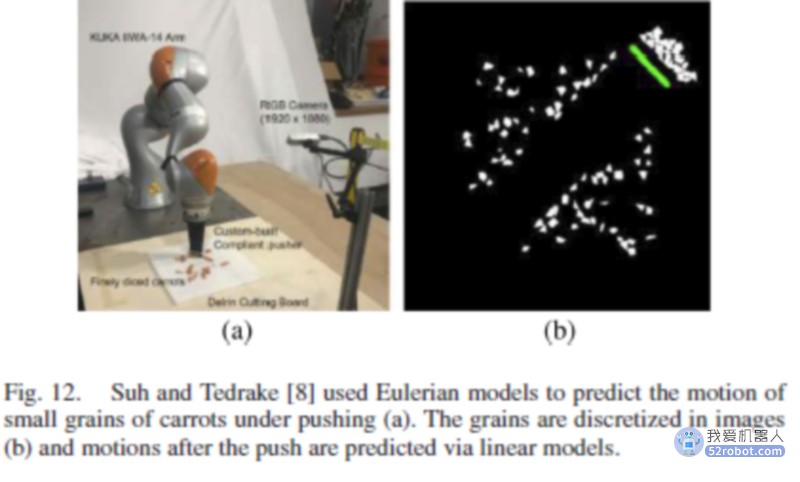
单对象/多对象/欧拉模型:单对象模型假设对象可以按顺序操作,并且忽略对象间的干扰。这个假设只在不那么混乱的情况下有效,例如,当对象被很好地分开时。多目标模型考虑了可能的对象间干扰。尽管这样的模型更通用,但处理多对象接触更具挑战性,这通常会降低效率和保真度。与标准的基于对象(拉格朗日)的离散化相比,欧拉模型使用空间离散化,其中场景的表示保持为图像或体积网格。拉格朗日模型由于其高保真度而更受欢迎,因为欧拉模型由于模糊了物体之间的边界而失去了准确性。然而,由于使用深度网络直接在图像空间中进行预测,欧拉模型越来越受欢迎,当有许多物体或物体-物体相互作用难以建模时,欧拉模型可以在计算上更有效。最近利用这些特征的工作如图所示。
2、 接触建模
经典接触模型对每个刚体使用拉格朗日表示,即预测每个刚体的6维构型。一对刚体之间的接触假定发生在一个离散的点集上。对于每个接触点,两个物体的相对速度和相互作用力分别被建模为两组沿法向和切向的互补条件。这种接触模型的变体已在各种现代刚体仿真软件中实现,并成功地预测了涉及许多物体的似是而非的运动。
丰富接触物理模拟被广泛用于离线验证和训练学习的多目标操作系统。模拟推送以检测对象之间的接触,然后用于计划推送操作的顺序。他们在检测到接触后立即重置模拟,因此在最终的运动计划中不会间接推动物体。
另一方面,只有少数文献选择在控制回路内进行在线物理模拟。在环仿真控制依赖于高度准确和高效的预测,这仍然很难用现成的模拟器实现。这部分是因为库仑摩擦问题的解一般都是非唯一的,而且依赖于接触点、法线和摩擦系数,这些接触点、法线和摩擦系数通常是有噪声的或不可观测的。我们注意到在某些情况下可以省略精确的接触建模。
最近关于杂乱物体和堆操作的研究对模拟器的有效性提出了越来越大的挑战。传统拉格朗日接触模型的内存和计算成本随着刚体数量的增加而迅速增长,限制了其可扩展性,仅限于数百个对象。该方法将物体的总体运动建模为物质流,其复杂性与物体的数量无关。计算物理学的大量研究,已经在欧拉表示下制定了接触模型,但它们还没有在操作系统中被利用。
3、 趋势和开放问题
1.特定于任务的模拟基准:刚体模拟器的能力已经被开发到极限,在过去的几年里,这些模拟器并没有引入主要的新功能。然而,我们仍然缺乏有效的度量标准、数据集和测试平台来比较对象操作上下文中预测模型的准确性。我们在表IV中的比较是定性的,基于粒度。另外两个关键的定量指标是效率(进行预测所需的计算成本)和保真度(预测结果与实际结果之间的差异)。
2.不确定性量化和建模:现有方法的一个主要疏忽是量化预测的不确定性,这可以帮助规划者选择高置信度的行动或反馈策略。例如,在推动操作中,支撑表面上的接触压力和摩擦分布是不可观察的,但会影响物体的整体运动。当涉及到接触时,表达不确定性尤其具有挑战性。当运动过程中有接触或没有接触时,使用简单分布(例如高斯分布)的信息传送无法捕获多模态后验信念。基于粒子的方法,即模拟初始状态和参数的蒙特卡罗采样,已用于此目的,但这些方法在规划中使用时往往计算成本太高。也许令人惊讶的是,不确定性与接触物体的数量没有直接关系。如果物体的特征尺度远小于末端执行器,那么几十个或几千个接触物体的总体行为可能会表现出很强的均匀性,例如在清洁灰尘或小颗粒时跟随扫帚的运动。
3.不完全观测下的基于学习的预测模型:最近,半参数和非参数、结构化、基于学习的模型已经成为一种很有前途的方法,可以获得预测能力,而无需对复杂控制方程进行艰苦的离散化。这些方法不编码任何物理规则,而是将对象之间的物理约束建模为图的边缘,并训练随机森林或神经网络来模拟约束求解器的行为。刚性、流体和粘弹性物体的复杂而真实的行为被再现。尽管其计算效率并不显著高于分析模型,但基于学习的模型可以在部分观测下进行预测。这是通过将不完全观测映射到潜在状态空间,并以联合方式训练状态估计器和潜在过渡模型来实现的。
第四部分:决策算法
生成机器人的行为涉及到一个运动规划器和一个控制器,其中规划器确定操作操作符的类型和参数,控制器在物理平台上实现。虽然操作控制本身是一个感兴趣的领域,但现有的单对象操作控制技术通常足以满足多对象设置。相反,主要的决策挑战是在运动规划阶段。与单对象操作规划不同,单对象操作规划的主要挑战是抓取规划和逆运动学,多对象操作规划要求对移动的对象进行仔细的排序,,有时还需要使用同时接触来一次移动多个对象。由于搜索空间很大,即使在简化的设置中,也很难找到(几乎)最优的运动计划。
1、规划问题的公式
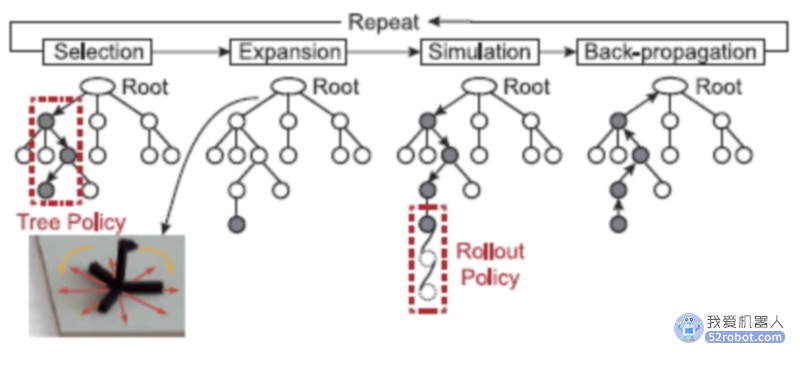
(1) 低级规划:给定一个预测模型,可以将多目标操作问题描述为低级运动的运动学运动规划问题或马尔可夫决策过程。接触的变化被认为是运动的副作用,没有明确的理由。在解决这些问题时,采用了宽度优先搜索、A*搜索、快速探索随机树(RRT)和蒙特卡罗树搜索(MCTS,如图所示)。这些方法可以成功地用于平面推送,但对于三维操作或抓取,每个操作操作成功的可能性都很低,导致整个任务的成功几率很小。相反,大多数作者将多对象操作问题描述为在高级操作中搜索。
(2)高级规划:在高级规划中,为机器人提供了一系列高级动作,例如拾取和放置,每一个动作都会改变系统的接触状态。每个动作通过一些参数集进一步参数化,例如,pick(X)和place(X,Y),其中X是对象标识,Y是位置,每个参数的域可以是离散的或连续的。计划者的职责是依次执行高级操作及其参数选择,以完成任务。这种方法的一个关键好处是,预测模型可以大大简化,从而忽略低级物理,而可以只模拟每个动作的前置条件和后置条件。例如,放置在没有障碍物的平面上的物体将停留在指定的位置。
(3)任务和运动计划:在某些问题中,例如头顶抓握的桌面重新排列,每个高级操作的可行性都得到了保证。但在其他问题中,一个高阶动作的可行性取决于一个可行的低阶动作的存在。评估存在性需要对几何结构进行推理和/或规划路径。例如,在可移动障碍物之间导航需要确定机器人是否能到达目标物体。对动作排序和寻找可行运动的一般问题已经研究了几十年,现在被称为任务-运动规划。
任务和运动规划(TAMP)中的一个关键挑战是在某些运动计划不可行的情况下分配任务规划和运动规划的工作量。一种策略是规划一系列任务,执行运动规划,并纳入失败运动计划的反馈,以阻止未来类似的任务级计划。然而,基于抽样规划的现代运动规划者只是在概率上完成的,并且确定一个固定的时间限制是具有挑战性的。多模态规划(MMP)通过对关节多步运动规划问题进行明确的推理来解决这一问题。任何动作的组合都会生成构型空间(模式)的离散图,每个构型空间(模式)都有自己的运动约束,它们相交于一些常见的过渡构型。然后将基于抽样的规划工作分布到各个模式。
尽管TAMP作为一种通用框架很有吸引力,但它在多对象操作方面有一些缺点。类似strip的符号信息的使用允许TAMP求解器在许多情况下自动生成有效的启发式,但是以适合识别无冲突任务序列的符号方式表示几何上的terference约束具有挑战性。此外,通用启发式通常比特定问题的启发式效率低得多。其次,对于打包等许多问题,性能瓶颈不是任务排序,而是在连续域中寻找最优的动作参数。最后,值得注意的是,解耦离散连续子问题可以产生次优运动计划。
2、多对象操作的困难
多目标操作的计算复杂度一直是一个非常有理论意义的领域,并且与多机器人协调问题密切相关。平面中协调移动矩形物体的问题至少是PSPACE-hard。Demaine等人表明,一般来说,解决导航问题是NP困难的。Kavraki和Kolountzakis证明了寻找分解两个平面形状的轨迹是NP完全的。一些操纵问题并不难解决,但很难找到最优解。
更复杂的非单调问题需要将对象移动到中间位置,有引入了另一个重排问题类LP-其中每个对象最多可以从其原始位置移动一段距离。这个问题类需要解决两个LP问题,一个是将对象移动到它们的中间目标,第二个是将对象移动到它们的最终目标。更一般的LPk问题类允许每个对象最多移动k次。然而,更复杂的问题要求机器人同时移动多个物体,但对这类问题的严格解决方案在文献中受到的关注相对较少。
3、特定任务解决方案技术
(1)分析启发式:现代重排计划器使用依赖图或其他数据结构加快了生成离散重排计划的过程。这类非单调实例与经典的“河内塔”难题相同。一种推(扫)多污垢颗粒[7]的启发式搜索方法使用分配到最近的目标作为启发式。当分配是互斥的,即没有两个对象可以占据同一个目标时,分配成本可以计算为对任何对象分配到目标的估计成本的最小值,这可以使用线性规划(例如,匈牙利算法)来求解。
(2)分而治之和回链方法:这些方法可用于加快对象排序的搜索速度。反向推理也用于放置计划,以确定需要为目标对象移到一边的对象。广度优先搜索在对象推送序列上向后执行,并限制于与目标位置重叠的对象。如果一个推送与另一个对象产生了接触,则该对象将被添加到候选对象列表中。在可以移除对象的单点问题的简化设置中,递归回链可以确定障碍物移除的顺序,以达到目标对象。贪心方法在单点和整理问题中通常是成功的,即通过优化某个值函数来重复选择下一个要移动的对象,然后调用低级规划器来计算轨迹。
(3)价值和q函数学习:为了提高贪婪方法的性能,一些研究人员考虑通过强化学习学习价值函数或q函数,然后可以贪婪地提升。Q函数Q(x, a)与价值函数V (x)高度相关,因为它们预测了在给定状态下采取行动的价值。
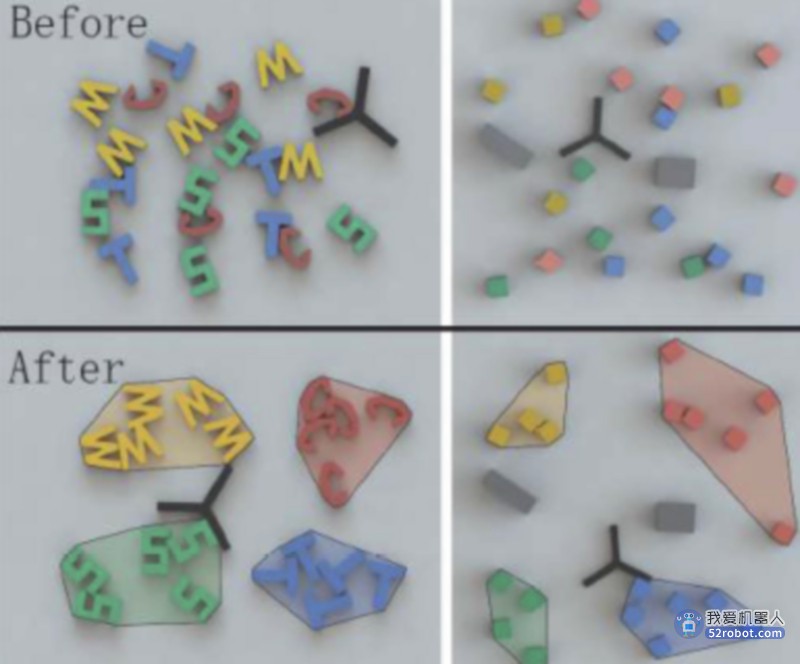
(4)策略学习:RL也被用于直接学习操作策略。最近的工作使用策略学习来解决机器人包装问题。还可以学习MCTS rollout步骤的策略,以改进在非终端节点上的值函数的评估。与随机铺开相比,该方法已被证明有相当大的提高成功率,并且能够对数十个对象进行排序(见图)。除了RL,还使用了从演示中学习MCTS rollout策略来推动重排任务。
(5)调整或学习动作采样策略:可以调整或学习基于采样的运动规划器、启发式搜索和MCTS选择的动作分布,以获得更好的性能。我们已经在第三节中讨论了可提供性预测,它限制了在决策中探索的行动的数量。在清理污垢[7]的任务中,采用聚类启发式来识别有希望的搜索动作。
4、 常见设计选择
在表V中,我们总结了在多个任务中使用的常见假设或设计选择,并分析了它们的含义

1.分离被广泛应用于重新排列、整理和打包分拣任务中,它假定物体之间的距离足够远,所以抓取总是可行的,物体与物体之间没有相互作用。
2.有限状态空间假设物体只能呈现一组离散的姿态。这允许使用组合搜索,它可以在允许的状态集内提供完整性或最优性保证。
3.有限动作空间假设机器人只能采取有限个可能的动作。
4.顺序假设限制了机器人同时移动多个物体。这也不允许多个机器人同时操作。
5.平面假设将机器人和/或物体移动的推理限制在一个平面上。感知也被简化了,因为系统的状态被完全观察到。在某些设置中,允许头顶抓取,但物体总是返回到一个平面。
6.单调假设限制了每个对象可以移动到目标位置的次数,包括LP *问题类。河内塔假设是一种特殊的形式,它假设物体可以移动多次,但在达到目标后保持固定。
7.操作操作员假设限制了对对象执行的可能高级操作的数量。三维抓取是最通用的,它考虑了物体和抓取器的全三维几何结构。平面抓取通常用于移动障碍物之间的导航,允许机器人在单点接触物体,以实现抓握接触。平面推在平面上使用非抓握推操作。
表V揭示了两个最有效的假设是顺序的和平面的,它们在早期和最近的工作中都被用于所有的任务。然而,在最近的研究中,有一种趋势是在排序任务时取消顺序假设,并考虑使用平面推动作的同时物体运动。另一种简化问题的有效方法是将问题的子类限制为pk或“河内谜题”。具有这种限制的方法通常可以提供完整性保证。其他假设(分离、有限状态和有限动作)专门用于导航和重排。
第五部分:趋势和开放问题
1、启发式与完整计划:由于操作任务大多是np困难的,相对较少的先前工作分析了计划优化性。其他工作要么是启发式的,要么只是提供概率完整性保证。在实践中,提供完整性或最优性保证的好处并没有得到很好的理解。另一方面,我们缺乏对各种启发式有效性的系统比较。未回答的问题包括:np难问题实例是否存在多项式时间逼近格式?启发式方法在多大程度上比完整或最优算法表现更差?我们注意到最近的工作]表明动态规划启发式在整理问题中具有接近最优的性能,这是很好的开始。
2、关于物体同时移动的推理:过去的绝大多数工作都假设一次只有一个物体移动,这导致了组合搜索中更好的可处理性,但效率有限。同时移动k个对象可以解决的问题被记为SPk。先前的工作使机器人能够同时在贪婪或后退视界中推动多个对象。但由于预测范围有限,无法证明完整性或最优性,为未来的理论工作留下了一个悬而未决的问题。
3、基于学习的方法:到目前为止,大多数基于学习的技术都使用了来自采样数据集的监督学习,要么通过模拟训练,要么在真实系统上训练。纯强化学习技术还没有广泛应用于多目标操作。这可能是由于强化学习对参数的敏感性,数据效率不足,模拟与真实的差异。此外,与训练不同的子网络模块相比,端到端视觉运动策略的可解释性较差,对参数调优不友好。
4、机制和行为协同设计:绝大多数关于多目标操作的研究假设机器人和末端执行器的固定设计。在多目标操作文献中,工具选择问题仍未得到充分重视,并且由于工具几何形状、材料和驱动特性的选择会影响规划的性能和完整性,因此探索工具选择问题将是有趣的。
5、反馈控制:绝大多数决策工作都没有明确地考虑不确定性和错误,如果采取任何方法,都可能涉及反应性的重新规划。贪心方法和后视界方法,如MCTS,非常适合重新规划。为了提高实际系统中多目标操作的鲁棒性,机器人可以通过算子来校正不确定性,或对预测中的不确定性进行明确推理。
声明:本站所有文章资源内容,如无特殊说明或标注,均为采集网络资源。如若本站内容侵犯了原著者的合法权益,可联系本站删除。











是什么?")









