机器人ChatGPT来了:大模型进现实世界,DeepMind重量级突破
给机器人发命令,从没这么简单过。
我们知道,在掌握了网络中的语言和图像之后,大模型终究要走进现实世界,「具身智能」应该是下一步发展的方向。
把大模型接入机器人,用简单的自然语言代替复杂指令形成具体行动规划,且无需额外数据和训练,这个愿景看起来很美好,但似乎也有些遥远。毕竟机器人领域,难是出了名的。
然而 AI 的进化速度比我们想象得还要快。
本周五,谷歌 DeepMind 宣布推出 RT-2:全球第一个控制机器人的视觉 - 语言 - 动作(VLA)模型。
现在不再用复杂指令,机器人也能直接像 ChatGPT 一样操纵了。

RT-2 到达了怎样的智能化程度?DeepMind 研究人员用机械臂展示了一下,跟 AI 说选择「已灭绝的动物」,手臂伸出,爪子张开落下,它抓住了恐龙玩偶。

在此之前,机器人无法可靠地理解它们从未见过的物体,更无法做把「灭绝动物」到「塑料恐龙玩偶」联系起来这种有关推理的事。
跟机器人说,把可乐罐给泰勒・斯威夫特:

看得出来这个机器人是真粉丝,对人类来说是个好消息。
ChatGPT 等大语言模型的发展,正在为机器人领域掀起一场革命,谷歌把最先进的语言模型安在机器人身上,让它们终于拥有了一颗人工大脑。
在 DeepMind 在最新提交的一篇论文中研究人员表示,RT-2 模型基于网络和机器人数据进行训练,利用了 Bard 等大型语言模型的研究进展,并将其与机器人数据相结合,新模型还可以理解英语以外的指令。

谷歌高管称,RT-2 是机器人制造和编程方式的重大飞跃。「由于这一变化,我们不得不重新考虑我们的整个研究规划了,」谷歌 DeepMind 机器人技术主管 Vincent Vanhoucke 表示。「之前所做的很多事情都完全变成无用功了。」
RT-2 是如何实现的?
DeepMind 这个 RT-2 拆开了读就是 Robotic Transformer —— 机器人的 transformer 模型。
想要让机器人能像科幻电影里一样听懂人话,展现生存能力,并不是件容易的事。相对于虚拟环境,真实的物理世界复杂而无序,机器人通常需要复杂的指令才能为人类做一些简单的事情。相反,人类本能地知道该怎么做。
此前,训练机器人需要很长时间,研究人员必须为不同任务单独建立解决方案,而借助 RT-2 的强大功能,机器人可以自己分析更多信息,自行推断下一步该做什么。
RT-2 建立在视觉 - 语言模型(VLM)的基础上,又创造了一种新的概念:视觉 - 语言 - 动作(VLA)模型,它可以从网络和机器人数据中进行学习,并将这些知识转化为机器人可以控制的通用指令。该模型甚至能够使用思维链提示,比如哪种饮料最适合疲惫的人 (能量饮料)。
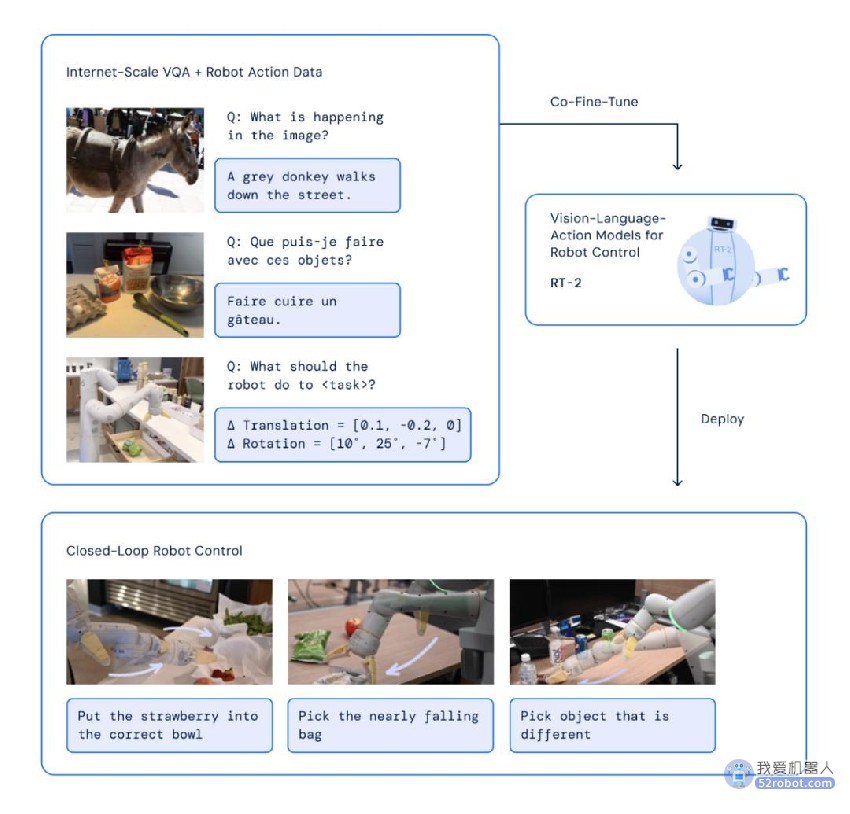
RT-2 架构及训练过程
其实早在去年,谷歌就曾推出过 RT-1 版本的机器人,只需要一个单一的预训练模型,RT-1 就能从不同的感官输入(如视觉、文本等)中生成指令,从而执行多种任务。
作为预训练模型,要想构建得好自然需要大量用于自监督学习的数据。RT-2 建立在 RT-1 的基础上,并且使用了 RT-1 的演示数据,这些数据是由 13 个机器人在办公室、厨房环境中收集的,历时 17 个月。
DeepMind 造出了 VLA 模型
前面我们已经提到 RT-2 建立在 VLM 基础之上,其中 VLMs 模型已经在 Web 规模的数据上训练完成,可用来执行诸如视觉问答、图像字幕生成或物体识别等任务。此外,研究人员还对先前提出的两个 VLM 模型 PaLI-X(Pathways Language and Image model)和 PaLM-E(Pathways Language model Embodied)进行了适应性调整,当做 RT-2 的主干,并将这些模型的视觉 - 语言 - 动作版本称为 RT-2-PaLI-X 以及 RT-2-PaLM-E 。
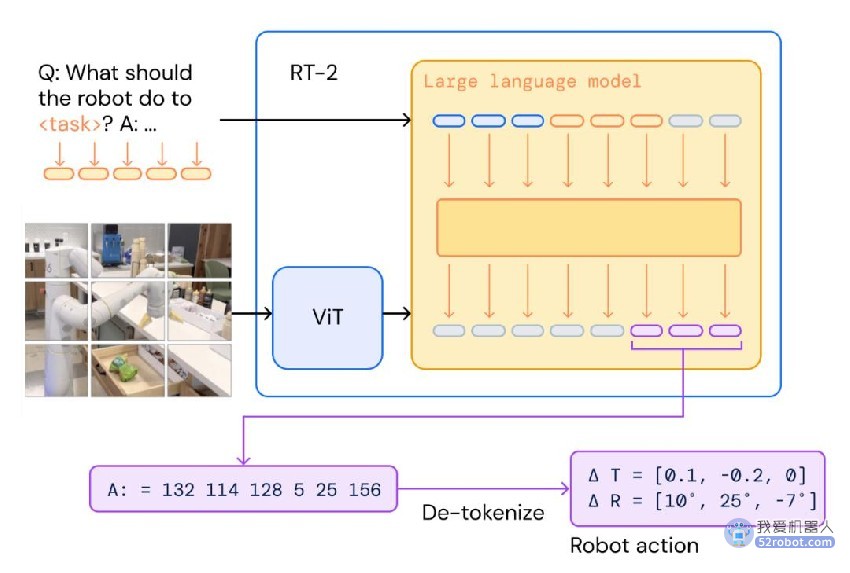
为了使视觉 - 语言模型能够控制机器人,还差对动作控制这一步。该研究采用了非常简单的方法:他们将机器人动作表示为另一种语言,即文本 token,并与 Web 规模的视觉 - 语言数据集一起进行训练。
对机器人的动作编码基于 Brohan 等人为 RT-1 模型提出的离散化方法。
如下图所示,该研究将机器人动作表示为文本字符串,这种字符串可以是机器人动作 token 编号的序列,例如「1 128 91 241 5 101 127 217」。

该字符串以一个标志开始,该标志指示机器人是继续还是终止当前情节,然后机器人根据指示改变末端执行器的位置和旋转以及机器人抓手等命令。
由于动作被表示为文本字符串,因此机器人执行动作命令就像执行字符串命令一样简单。有了这种表示,我们可以直接对现有的视觉 - 语言模型进行微调,并将其转换为视觉 - 语言 - 动作模型。
在推理过程中,文本 token 被分解为机器人动作,从而实现闭环控制。
实验
研究人员对 RT-2 模型进行了一系列定性和定量实验。
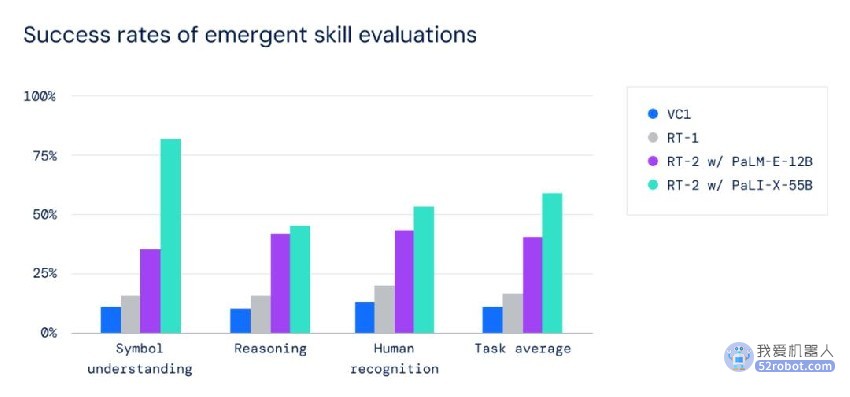
下图展示了 RT-2 在语义理解和基本推理方面的性能。例如,对于「把草莓放进正确的碗里」这一项任务,RT-2 不仅需要对草莓和碗进行表征理解,还需要在场景上下文中进行推理,以知道草莓应该与相似的水果放在一起。而对于「拾起即将从桌子上掉下来的袋子」这一任务,RT-2 需要理解袋子的物理属性,以消除两个袋子之间的歧义并识别处于不稳定位置的物体。
需要说明的是,所有这些场景中测试的交互过程在机器人数据中从未见过。

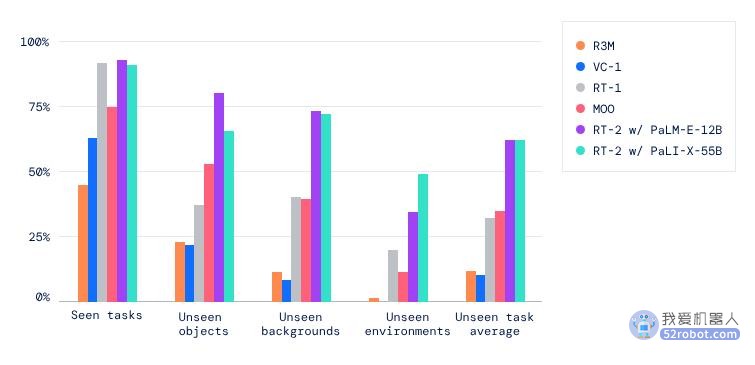
下图表明在四个基准测试上,RT-2 模型优于之前的 RT-1 和视觉预训练 (VC-1) 基线。
RT-2 保留了机器人在原始任务上的性能,并提高了机器人在以前未见过场景中的性能,从 RT-1 的 32% 提高到 62%。
一系列结果表明,视觉 - 语言模型(VLM)是可以转化为强大的视觉 - 语言 - 动作(VLA)模型的,通过将 VLM 预训练与机器人数据相结合,可以直接控制机器人。
和 ChatGPT 类似,这样的能力如果大规模应用起来,世界估计会发生不小的变化。不过谷歌没有立即应用 RT-2 机器人的计划,只表示研究人员相信这些能理解人话的机器人绝不只会停留在展示能力的层面上。
简单想象一下,具有内置语言模型的机器人可以放入仓库、帮你抓药,甚至可以用作家庭助理 —— 折叠衣物、从洗碗机中取出物品、在房子周围收拾东西。

它可能真正开启了在有人环境下使用机器人的大门,所有需要体力劳动的方向都可以接手 —— 就是之前 OpenAI 有关的报告中,大模型影响不到的那部分,现在也能被覆盖。
具身智能,离我们不远了?
最近一段时间,具身智能是大量研究者正在探索的方向。本月斯坦福大学李飞飞团队就展示了一些新成果,通过大语言模型加视觉语言模型,AI 能在 3D 空间分析规划,指导机器人行动。

稚晖君的通用人形机器人创业公司「智元机器人(Agibot)」昨天晚上放出的视频,也展示了基于大语言模型的机器人行为自动编排和任务执行能力。

预计在 8 月,稚晖君的公司即将对外展示最近取得的一些成果。
可见在大模型领域里,还有大事即将发生。
参考内容:
https://www.deepmind.com/blog/rt-2-new-model-translates-vision-and-language-into-action
https://www.blog.google/technology/ai/google-deepmind-rt2-robotics-vla-model/
https://www.theverge.com/2023/7/28/23811109/google-smart-robot-generative-ai
https://www.nytimes.com/2023/07/28/technology/google-robots-ai.html
https://www.bilibili.com/video/BV1Uu4y1274k/
声明:本站所有文章资源内容,如无特殊说明或标注,均为采集网络资源。如若本站内容侵犯了原著者的合法权益,可联系本站删除。





















